Getting Started¶
Bambi requires a working Python interpreter (either 2.7+ or 3+). We recommend installing Python and key numerical libraries using the Anaconda Distribution, which has one-click installers available on all major platforms.
Assuming a standard Python environment is installed on your machine (including pip), Bambi itself can be installed in one line using pip:
pip install bambi
Alternatively, if you want the bleeding edge version of the package, you can install from GitHub:
pip install git+https://github.com/bambinos/bambi.git
Quickstart¶
Suppose we have data for a typical within-subjects psychology experiment with 2 experimental conditions. Stimuli are nested within condition, and subjects are crossed with condition. We want to fit a model predicting reaction time (RT) from the fixed effect of condition, random intercepts for subjects, random condition slopes for students, and random intercepts for stimuli. We can fit this model and summarize its results as follows in bambi:
from bambi import Model
# Assume we already have our data loaded
model = Model(data)
results = model.fit(
'rt ~ condition',
random=['condition|subject', '1|stimulus'],
samples=5000, chains=2
)
results[1000:].plot()
results[1000:].summary()
User Guide¶
Creating a model¶
Creating a new model in Bambi is simple:
from bambi import Model
import pandas as pd
# Read in a tab-delimited file containing our data
data = pd.read_table('my_data.txt', sep='\t')
# Initialize the model
model = Model(data)
Typically, we’ll initialize a bambi Model by passing it a pandas DataFrame as the only argument. We get back a model that we can immediately start adding terms to.
Data format¶
As with most mixed effect modeling packages, Bambi expects data in “long” format–meaning that each row should reflect a single observation at the most fine-grained level of analysis. For example, given a model where students are nested into classrooms and classrooms are nested into schools, we would want data with the following kind of structure:
student |
gender |
gpa |
class |
school |
|---|---|---|---|---|
1 |
F |
3.4 |
1 |
1 |
2 |
F |
3.7 |
1 |
1 |
3 |
M |
2.2 |
1 |
1 |
4 |
F |
3.9 |
2 |
1 |
5 |
M |
3.6 |
2 |
1 |
6 |
M |
3.5 |
2 |
1 |
7 |
F |
2.8 |
3 |
2 |
8 |
M |
3.9 |
3 |
2 |
9 |
F |
4.0 |
3 |
2 |
Model specification¶
Bambi provides a flexible way to specify models that makes it easy not only to specify the terms.
Formula-based specification¶
Models are specified in Bambi using a formula-based syntax similar to what one might find in R packages like lme4 or nlme. A couple of examples that illustrate the breadth of models that can be easily specified in Bambi:
# Fixed effects only
results = model.fit('rt ~ attention + color')
# Fixed effects and random intercepts for subject
results = model.fit(
'y ~ 0 + gender + condition*age',
random=['1|subject']
)
# Multiple, complex random effects with both
# random slopes and random intercepts
results = model.fit(
'y ~ 0 + gender',
random=['condition|subject', 'condition|site']
)
Each of the above examples specifies a full model that will immediately be fitted using either PyMC3 or Stan (more on that below).
Notice how, in contrast to lme4 (but similar to nlme), fixed and random effects are specified separately in Bambi. We describe the syntax and operators supported by each type of effect below; briefly, however, the fixed effects specification relies on patsy, and hence formulas are parsed almost exactly the same way as in R. Random effects terms must be specified one at a time.
Incremental specification¶
Although models can be fit in one line, as above, an alternative approach that is more verbose but sometimes clearer is to enter one or more terms into the model incrementally. The add() method takes essentially the same arguments as the fit() method, but doesn’t automatically start compiling and fitting the model.
from bambi import Model, Prior
# Initialize model
model = Model(data)
# Continuous fixed effect (in this case, a binary indicator);
# will also add intercept automatically unless it is explicitly
# supppressed.
model.add('condition')
# Categorical fixed effect, setting a narrow prior. We explicitly
# name the columns that should be interpreted as categoricals.
# Note that if age_group is already represented as a categorical
# variable in the DataFrame, the categorical argument is
# unnecessary. But it's good practice to be explicit about what
# the categorical variables are, as users sometimes inadvertently
# pass numeric columns that are intended to be treated as
# categorical variables, and Bambi has no way of knowing this.
model.add(
'age_group',
categorical=['age_group'],
priors={'age_group': 'narrow'}
)
# Random subject intercepts
model.add(random=['subj'], categorical=['subj'])
# Random condition slopes distributed over subjects
model.add(random=['0+condition|subj'])
# Add outcome variable
model.add('y ~ 0')
# Fit the model and save results
results = model.fit()
As the above example illustrates, the only mandatory argument to add is a string giving the name of the dataset column to use for the term. If no other arguments are specified, the corresponding variable will be modeled as a fixed effect with a normally-distributed prior (a detailed explanation of how priors are handled in Bambi can be found below). The type of variable (i.e., categorical or continuous) will be determined based on the dtype of the column in the pandas DataFrame, so it’s a good idea to make sure all variables are assigned the correct dtype when you first read in the data. You can also force continuous variables to be treated as categorical factors by passing them as a list to the categorical argument (e.g., add_term('subject + condition + extraversion', categorical=['subject'])).
To specify that a term should be modeled as a random effect, pass the formula to the random argument (e.g., random='1|subj'). The specification of random intercepts vs. slopes is handled as in other packages, or in the full specification passed to a single fit() call. For example, add(random=['1|site', '0+condition|subject']) would add random condition slopes distributed over subjects (without subject intercepts), as well as random intercepts for sites.
Notes on fixed and random effects in Bambi¶
As noted above, Bambi handles fixed and random effects separately. The fixed effects specification relies on the patsy package, which supports nearly all of the standard formula operators handled in base R–including :, *, -, etc. Unfortunately, patsy doesn’t support grouping operators, so random effects are handled separately in Bambi. All terms must be passed in as elements in a list (though each individual term can be as complex as a normal fixed effect specification). For example:
random_terms = [
# Random student intercepts
'1|student',
# Random classroom intercepts
'1|classroom',
# Random treatment slopes distributed over schools;
# school intercepts will also be automtically added
'treatment|school',
# A random set of subject slopes for each level of
# the combination of factors a and b, with subject
# intercepts excluded
'0+a*b|subject'
]
model.add(random=random_terms)
Coding of categorical variables¶
When a categorical fixed effect with N levels is added to a model, by default, it is coded by N-1 dummy variables (i.e., reduced-rank coding). For example, suppose we write 'y ~ condition + age + gender', where condition is a categorical variable with 4 levels, and age and gender are continuous variables. Then our model would contain an intercept term (added to the model by default, as in R), three dummy-coded variables (each contrasting the first level of condition with one of the subsequent levels), and continuous predictors for age and gender. Suppose, however, that we would rather use full-rank coding of conditions. If we explicitly remove the intercept–as in 'y ~ 0 + condition + age + gender'–then we get the desired effect. Now, the intercept is no longer included, and condition will be coded using 4 dummy indicators–each one coding for the presence or absence of the respective condition, without reference to the other conditions.
Random effects are handled in a comparable way. When adding random intercepts, coding is always full-rank (e.g., when adding random intercepts for 100 schools, one gets 100 dummy-coded indicators coding each school separately, and not 99 indicators contrasting each school with the very first one). For random slopes, coding proceeds the same way as for fixed effects. The random effects specification ['condition|subject'] would add an intercept for each subject, plus N-1 condition slopes (each coded with respect to the first, omitted, level as the referent). If we instead specify ['0+condition|subject'], we get N condition slopes and no intercepts.
Fitting the model¶
Once a model is fully specified, we need to run the PyMC3 or Stan sampler to generate parameter estimates. If we’re using the one-line fit() interface, sampling will begin right away (by default, using the PyMC3 back-end):
model = Model(data)
results = model.fit(
'rt ~ condition + gender + age',
random='condition|subject'
)
The above code will obtain 1,000 samples (the default value) and return them as a ModelResults instance (for more details, see the Results section). In this case, the fit() method accepts optional keyword arguments to pass onto PyMC3’s sample() method, so any methods accepted by sample() can be specified here. We can also explicitly set the number of samples via the samples argument. For example, if we call fit('y ~ X1', samples=2000, chains=2), the PyMC3 sampler will sample two chains in parallel, drawing 2,000 samples for each one. We could also specify starting parameter values, the step function to use, and so on (for full details, see the PyMC3 documentation).
Alternatively, if we’re building our model incrementally, we can specify our model in steps, and only call fit() once the model is complete:
model = Model(data)
model.add('food_type', categorical=['food_type'])
model.add(random='1|subject')
...
results = model.fit(samples=5000)
Building the model¶
When fit() is called, Bambi internally performs two separate steps. First, the model is built or compiled, via a build() call. During the build, the PyMC3 model is compiled by Theano, in order to optimize the underlying Theano graph and improve sampling efficiency. This process can be fairly time-consuming, depending on the size and complexity of the model. It’s possible to build the model explicitly, without beginning the sampling process, by calling build() directly on the model:
model = Model(data)
model.add(
'rt ~ condition + gender + age',
random='condition|subject'
)
model.build()
Alternatively, the same result can be achieved using the run argument to fit():
model = Model(data)
model.fit(
'rt ~ condition + gender + age',
random='condition|subject',
run=False
)
In both of the above cases, sampling won’t actually start until fit() is called (in the latter case, a second time). The only difference between the two above snippets is that the former will compile the model (note the explicit build() call) whereas the latter will not.
Building without sampling can be useful if we want to inspect the internal PyMC3 model before we start the (potentially long) sampling process. Once we’re satisfied, and wish to run the sampler, we can then simply call model.fit(), and the sampler will start running.
Alternative back-ends¶
Bambi defaults to using the NUTS MCMC sampler implemented in the PyMC3 package for all model-fitting. However, Bambi also supports the Stan MCMC sampling package, via the PyStan interface. To switch from PyMC3 to Stan, all you have to do is specify backend='stan' in the fit() call:
model = Model(data)
results = model.fit(
'rt ~ condition + gender + age',
random='condition|subject',
backend='stan'
)
From the user’s standpoint, the change from PyMC3 to Stan (or vice versa) will usually be completely invisible. Unless we want to muck around in the internals of the backends, the API is identical no matter which back-end we’re using. This frees us up to easily compare different back-ends in terms of speed and/or estimates (assuming the sampler has converged, the two back-ends shoul produce virtually identical estimates for all models, but performance could theoretically differ).
Which back-end should I use?¶
PyMC3 and Stan are both under active and intensive development, so the pros and cons of using either back-end may change over time. However, as of this writing (March 2017), our general sense is that Stan is typically faster than PyMC3 (in terms of both compilation and sampling time), but offers less flexibility when called from Bambi. The decreased flexibility is not due to inherent limitations in Stan itself, but reflects the fact that PyMC3 has the major advantage of being written entirely in Python. This means that Bambi is much more tightly integrated with PyMC3, and users can easily take advantage of virtually all of PyMC3’s functionality. Indeed, reaching into Bambi for the PyMC Model and MultiTrace is trivial:
# Initialize and fit Bambi model
import bambi as bm
import pymc3 as pm
model = bm.Model('data.csv')
results = model.fit(...) # we fit some model
# Grab the PyMC3 Model object and the fitted MultiTrace
pm_model = model.backend.model
pm_trace = model.backend.trace
# Now we can use any PyMC3 method that operates on MultiTraces
pm.traceplot(pm_trace)
As discussed below in A note on priors in stan, a secondary benefit of using PyMC3 rather than Stan is that users have much greater flexibility regarding the choice of priors when using the former back-end.
In general, then, our recommendation is that most users are better off sticking with the PyMC3 back-end unless the model being fit is relatively large and involves no unusual priors, at which point it is worth experimenting with the Stan back-end to see if significant speed gains can be obtained.
Specifying priors¶
Bayesian inference requires one to specify prior probability distributions that represent the analyst’s belief (in advance of seeing the data) about the likely values of the model parameters. In practice, analysts often lack sufficient information to formulate well-defined priors, and instead opt to use “weakly informative” priors that mainly serve to keep the model from exploring completely pathological parts of the parameter space (e.g., when defining a prior on the distribution of human heights, a value of 3,000 cms should be assigned a probability of exactly 0).
By default, Bambi will intelligently generate weakly informative priors for all model terms, by loosely scaling them to the observed data (details can be found in this article. While the default priors will behave well in most typical settings, there are many cases where an analyst will want to specify their own priors–and in general, when informative priors are available, it’s a good idea to use them.
Different ways of specifying priors¶
Bambi provides two ways to specify a custom prior. First, one can manually specify only the scale of the prior, while retaining the default distribution. By default, Bambi sets “weakly informative” priors on all fixed and random effects. Priors are specified on a (generalized) partial correlation scale that quantifies the expected standardized contribution of each individual term to the outcome variable when controlling for other terms. The default “wide” setting sets the scale of a fixed effect prior to sqrt(1/3) = 0.577 on the partial correlation scale, which is the standard deviation of a flat prior from -1 to +1. This correlation-level scale value then gets translated to a Normal prior at the slope level, centered on 0 by default, with a correspondingly wide variance. This process results in a weakly informative (rather than non-informative) prior distribution whose width can be tuned in a simple, intuitive way. More detailed information about how the default priors work can be found in this technical paper.
In cases where we want to keep the default prior distributions, but alter their scale, we can specify either a numeric scale value or pass the name of a predefined constant. For example:
model = Model(data)
# Add condition to the model as a fixed effect with a very
# wide prior
model.add('condition', prior='superwide')
# Add random subject intercepts to the model, with a narrow
# prior on their standard deviation
model.add(random='1|subject', prior=0.1)
Predefined named scales include “superwide” (scale = 0.8), “wide” (0.577; the default), “medium” (0.4), and “narrow” (0.2). The theoretical maximum scale value is 1.0, which specifies a distribution of partial correlations with half of the values at -1 and the other half at +1. Scale values closer to 0 are considered more “informative” and tend to induce more shrinkage in the parameter estimates.
The ability to specify prior scales this way is helpful, but also limited: we will sometimes find ourselves wanting to use something other than a Normal distribution to model our priors. Fortunately, Bambi is built on top of PyMC3, which means that we can seamlessly use any of the over 40 Distribution classes defined in PyMC3. We can specify such priors in Bambi using the Prior class, which initializes with a name argument (which must map on exactly to the name of a valid PyMC3 Distribution) followed by any of the parameters accepted by the corresponding distribution. For example:
from bambi import Prior
# A laplace prior with mean of 0 and scale of 10
my_favorite_prior = Prior('Laplace', mu=0., b=10)
# Set the prior when adding a term to the model;
# more details on this below.
priors = {'1|subject': my_favorite_prior}
results = model.fit(
'y ~ condition',
random='1|subject',
priors=priors
)
Priors specified using the Prior class can be nested to arbitrary depths–meaning, we can set any of a given prior’s argument to point to another Prior instance. This is particularly useful when specifying hierarchical priors on random effects, where the individual random slopes or intercepts are constrained to share a common source distribution:
subject_sd = Prior('HalfCauchy', beta=5)
subject_prior = Prior('Normal', mu=0, sd=subject_sd)
priors = {'1|subject': my_favorite_prior}
results = model.fit(
'y ~ condition',
random='1|subject',
priors=priors
)
The above prior specification indicates that the individual subject intercepts are to be treated as if they are randomly sampled from the same underlying normal distribution, where the variance of that normal distribution is parameterized by a separate hyperprior (a half-cauchy with beta = 5).
A note on priors in Stan¶
The above discussion assumes that one is using the PyMC3 backend for model fitting. Although custom priors can be specified using the same syntax when using the Stan backend, the variety of supported prior distributions is much more limited (the technical reason for this is that the Stan back-end requires us to explicitly add each distribution we wish to support, whereas the PyMC3 backend is able to seamlessly and automatically use any distribution supported within PyMC3). If you plan to use uncommon distributions for your priors, we encourage you to use the PyMC3 back-end (which is also the default—so if you didn’t explicitly specify the back-end, you’re probably already using PyMC3). Note also that regardless of which backend you use, all prior distributions use the names found in PyMC3, and not in Stan or any other package (e.g., in Stan, a half-Cauchy prior is specified as a full Cauchy prior with a lower bound of 0, but in Bambi, you would use the PyMC3 convention and pass a 'HalfCauchy' prior).
Mapping priors onto terms¶
Once we’ve defined custom priors for one or more term, we need to map them onto those terms in our model. Bambi allows us to do this efficiently by passing a dictionary of term -> prior mappings in any fit() or add() call (and also via a separate set_priors() method on the Model class). The keys of the dictionary the names of terms, and the values are the desired priors. There are also fixed and random arguments that make it easy to apply the same priors to all fixed or random effects in the model. Some examples:
model = Model(data)
# Example 1: set each prior by name. Note that we can set the same
# prior for multiple terms at once, by passing a tuple in the key.
priors = {
'X1': 0.3,
'X2': 'normal',
('X3', 'X4'): Prior('ZeroInflatedPoisson', theta=10, psi=0.5)
}
results = model.fit(
'y ~ X1 + X2',
random=['1|X3', '1|X4'],
priors=priors
)
# Example 2: specify priors for all fixed effects and all random
# effects, except for X1, which still gets its own custom prior.
priors = {
'X1': 0.3,
'fixed': Prior('Normal', sd=100),
'random': 'wide'
}
results = model.fit(
'y ~ X1 + X2',
random=['1|X3', '1|X4'],
priors=priors
)
Notice how this interface allows us to specify terms either by name (including passing tuples as keys in cases where we want multiple terms to share the same prior), or by term type (i.e., to set the same prior on all fixed or random effects). If we pass both named priors and fixed or random effects defaults, the former will take precedence over the latter (in the above example, the prior for 'X1' will be 0.3).
If we prefer, we can also set priors outside of the fit() (or add()) calls, using the set_priors method:
# Specify model but don't build/sample just yet
model.fit('y ~ X1 + X3 + X4', random='1|X2', run=False)
# Specify priors—produces same result as in Example 2 above
model.set_priors(
{'X1': 0.3},
fixed=Prior('Normal', sd=100),
random='wide'
)
# Now sample
results = model.fit(samples=5000)
Here we stipulate that terms X1 and X4 will use the same normal prior, X2 will use a different normal prior with a uniform hyperprior on its standard deviation, and all other fixed effects will use the default prior with a scale of 0.5.
It’s important to note that explicitly setting priors by passing in Prior objects will disable Bambi’s default behavior of scaling priors to the data in order to ensure that they remain weakly informative. This means that if you specify your own prior, you have to be sure not only to specify the distribution you want, but also any relevant scale parameters. For example, the 0.5 in Prior('Normal', mu=0, sd=0.5) will be specified on the scale of the data, not the bounded partial correlation scale that Bambi uses for default priors. This means that if your outcome variable has a mean value of 10,000 and a standard deviation of, say, 1,000, you could potentially have some problems getting the model to produce reasonable estimates, since from the perspective of the data, you’re specifying an extremely strong prior.
Generalized linear mixed models¶
Bambi supports the construction of mixed models with non-normal response distributions (i.e., generalized linear mixed models, or GLMMs). GLMMs are specified in the same way as LMMs, except that the user must specify the distribution to use for the response, and (optionally) the link function with which to transform the linear model prediction into the desired non-normal response. The easiest way to construct a GLMM is to simple set the family argument in the fit() call:
model = Model(data)
results = model.fit(
'graduate ~ attendance_record + GPA',
random='1|school',
family='bernoulli'
)
If no link argument is explicitly set (see below), the canonical link function (or an otherwise sensible default) will be used. The following table summarizes the currently available families and their associated links (the default is gaussian):
Family name |
Response distribution |
Default link |
|---|---|---|
gaussian |
Normal |
identity |
bernoulli |
Bernoulli |
logit |
poisson |
Poisson |
log |
Families¶
Following the convention used in many R packages, the response distribution to use for a GLMM is specified in a Family class that indicates how the response variable is distributed, as well as the link function transforming the linear response to a non-linear one. Although the easiest way to specify a family is by name, using one of the options listed in the table above, users can also create and use their own family, providing enormous flexibility (note, again, that custom specifications are only guaranteed to work with the PyMC3 back-end; results may be unpredictable when using Stan, as noted in A note on priors in Stan). In the following example, we show how the built-in ‘bernoulli’ family could be constructed on-the-fly:
from bambi import Family, Prior
import theano.tensor as tt
# Specify how the Bernoulli p parameter is distributed
prior_p = Prior('Beta', alpha=2, beta=2)
# The response variable distribution
prior = Prior('Bernoulli', p=prior_p)
# Set the link function. Alternatively, we could just set
# the link to 'logit', since it's already built into Bambi.
# Note that we could pass in our own function here; the link
# function doesn't have to be predefined.
link = tt.nnet.sigmoid
# Construct the family
new_fam = Family('bernoulli', prior=prior, link=link, parent='p')
# Now it's business as usual
model = Model(data)
results = model.fit(
'graduate ~ attendance_record + GPA',
random='1|school',
family=new_fam
)
The above example produces results identical to simply setting family='bernoulli'.
One (minor) complication in specifying a custom Family is that the link function must be able to operate over theano tensors rather than numpy arrays, so you’ll probably need to rely on tensor operations provided in theano.tensor (many of which are also wrapped by PyMC3) when defining a new link.
Results¶
When a model is fitted, it returns a ModelResults object (usually of subclass MCMCResults) containing methods for plotting and summarizing results. At present, functionality here is fairly limited; Bambi only provides basic plotting and summarization tools.
Plotting¶
To visualize a PyMC3-generated plot of the posterior estimates and sample traces for all parameters, simply call the MCMCResults object’s .plot() method:
model = Model(data)
results = model.fit(
'value ~ condition',
random='1|uid',
samples=1250,
chains=4
)
# Drop the first 100 burn-in samples from each chain and plot
results[100:].plot()
This produces a plot like the following:
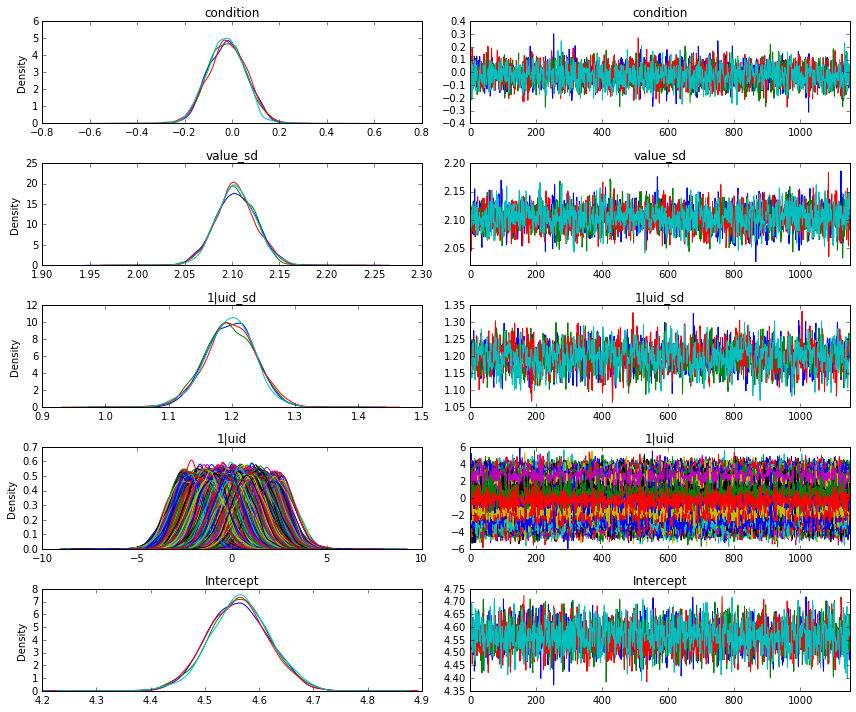
More details on this plot are available in the PyMC3 documentation.
Summarizing¶
If you prefer numerical summaries of the posterior estimates, you can use the .summary() method, which provides a pandas DataFrame with some key summary and diagnostic info on the model parameters, such as the 95% highest posterior density intervals:
results[100:].summary()
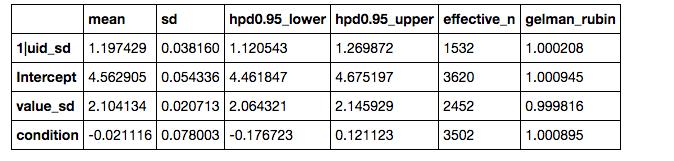
By default the .summary() method hides the random effects (which can easily clutter the output when there are many of them) and transformed variables of parameters that are used internally during the model estimation, but you can view all of these by adjusting the arguments to ranefs and transformed, respectively:
results[100:].summary(ranefs=True)
results[100:].plot(transformed=True)
If you want to view summaries or plots for only specific parameters, you can pass a list of parameter names inside the brackets in addition to the slice operator:
# show the names of all parameters stored in the MCMCResults object
results.names
# these two calls are equivalent
results[100:, ['Intercept', 'condition']].plot()
results[['Intercept', 'condition'], 100:].plot()
And if you want to access the MCMC samples directly, you can use the .to_df() method to retrieve the MCMC samples (after concatening any separate MCMC chains) in a nice, neat pandas DataFrame:
results[100:].to_df(ranefs=True)
You can find detailed, worked examples of fitting Bambi models and working with the results in the example notebooks here.
Accessing back-end objects¶
Bambi is just a high-level interface to other statistical packages; as such, it uses other packages as computational back-ends. Internally, Bambi stores virtually all objects generated by backends like PyMC3, making it easy for users to retrieve, inspect, and modify those objects. For example, the Model class created by PyMC3 (as opposed to the Bambi class of the same name) is accessible from model.backend.model. For models fitted with a PyMC3 sampler, the resulting MultiTrace object is stored in model.backend.trace (though it can also be accessed via Bambi’s ModelResults instance).