Splines¶
This example shows how to specify and fit a spline regression in Bambi. This example is based on this example from the PyMC docs.
[1]:
import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
[2]:
az.style.use("arviz-darkgrid")
SEED = 7355608
Load Cherry Blossom data¶
Richard McElreath popularized the Cherry Blossom dataset in the second edition of his excellent book Statistical Rethinking. This data represents the day in the year when the first bloom is observed for Japanese cherry blossoms between years 801 and 2015. In his book, Richard McElreath uses this dataset to introduce Basis Splines, or B-Splines in short.
Here we use Bambi to fit a linear model using B-Splines with the Cherry Blossom data. This dataset can be loaded with Bambi as follows:
[3]:
data = bmb.load_data("cherry_blossoms")
data
[3]:
| year | doy | temp | temp_upper | temp_lower | |
|---|---|---|---|---|---|
| 0 | 801 | NaN | NaN | NaN | NaN |
| 1 | 802 | NaN | NaN | NaN | NaN |
| 2 | 803 | NaN | NaN | NaN | NaN |
| 3 | 804 | NaN | NaN | NaN | NaN |
| 4 | 805 | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... |
| 1210 | 2011 | 99.0 | NaN | NaN | NaN |
| 1211 | 2012 | 101.0 | NaN | NaN | NaN |
| 1212 | 2013 | 93.0 | NaN | NaN | NaN |
| 1213 | 2014 | 94.0 | NaN | NaN | NaN |
| 1214 | 2015 | 93.0 | NaN | NaN | NaN |
1215 rows × 5 columns
The variable we are interested in modeling is "doy", which stands for Day of Year. Also notice this variable contains several missing value which are discarded next.
[4]:
data = data.dropna(subset=["doy"]).reset_index(drop=True)
data.shape
[4]:
(827, 5)
Explore the data¶
Let’s get started by creating a scatterplot to explore the values of "doy" for each year in the dataset.
[5]:
# We create a function because this plot is going to be used again later
def plot_scatter(data, figsize=(10, 6)):
_, ax = plt.subplots(figsize=figsize)
ax.scatter(data["year"], data["doy"], alpha=0.4, s=30)
ax.set_title("Day of the first bloom per year")
ax.set_xlabel("Year")
ax.set_ylabel("Days of the first bloom")
return ax
[6]:
plot_scatter(data);
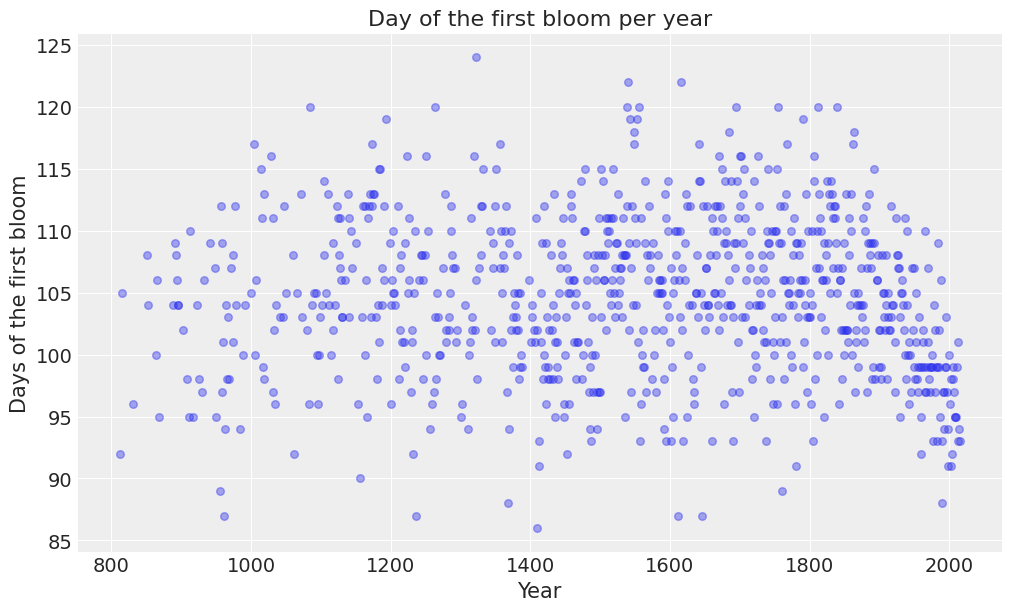
We can observe the day of the first bloom ranges between 85 and 125 approximately, which correspond to late March and early May respectively. On average, the first bloom occurs on the 105th day of the year, which is middle April.
Determine knots¶
The spline will have 15 knots. These knots are the boundaries of the basis functions. These knots split the range of the "year" variable into 16 contiguous sections. The basis functions make up a piecewise continuous polynomial, and so they are enforced to meet at the knots. We use the default degree for each piecewise polynomial, which is 3. The result is known as a cubic spline.
Because of using quantiles and not having observations for all the years in the time window under study, the knots are distributed unevenly over the range of "year" in such a way that the same proportion of values fall between each section.
[7]:
num_knots = 15
knots = np.quantile(data["year"], np.linspace(0, 1, num_knots))
[8]:
def plot_knots(knots, ax):
for knot in knots:
ax.axvline(knot, color="0.1", alpha=0.4)
return ax
[9]:
ax = plot_scatter(data)
plot_knots(knots, ax);
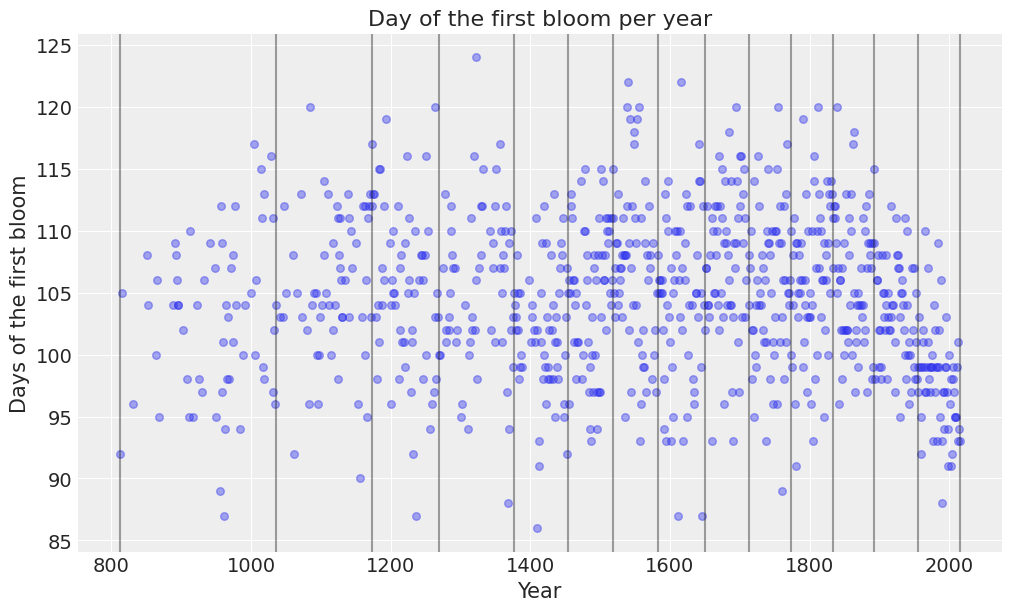
The previous chart makes it easy to see the knots, represented by the vertical lines, are spaced unevenly over the years.
The model¶
The B-spline model we are about to create is simply a linear regression model with synthetic predictor variables. These predictors are the basis functions that are derived from the original year predictor.
In math notation, we usa a \(\text{Normal}\) distribution for the conditional distribution of \(Y\) when \(X = x_i\), i.e. \(Y_i\), the distribution of the day of the first bloom in a given year.
So far, this looks like a regular linear regression model. The next line is where the spline comes into play:
The line above tells that for each observation \(i\), the mean is influenced by all the basis functions (going from \(k=1\) to \(k=K\)), plus an intercept \(\alpha\). The \(w_k\) values in the summation are the regression coefficients of each of the basis functions, and the \(B_k\) are the values of the basis functions.
Finally, we will be using the following priors
where \(j\) indexes each of the contiguous sections given by the knots
[10]:
# We only pass the internal knots to the `bs()` function.
iknots = knots[1:-1]
# Define dictionary of priors
priors = {
"Intercept": bmb.Prior("Normal", mu=100, sigma=10),
"common": bmb.Prior("Normal", mu=0, sigma=10),
"sigma": bmb.Prior("Exponential", lam=1)
}
# Define model
# The intercept=True means the basis also spans the intercept, as originally done in the book example.
model = bmb.Model("doy ~ bs(year, knots=iknots, intercept=True)", data, priors=priors)
model
[10]:
Formula: doy ~ bs(year, knots=iknots, intercept=True)
Family name: Gaussian
Link: identity
Observations: 827
Priors:
Common-level effects
Intercept ~ Normal(mu: 100, sigma: 10)
bs(year, knots = iknots, intercept = True) ~ Normal(mu: 0, sigma: 10)
Auxiliary parameters
sigma ~ Exponential(lam: 1)
Let’s create a function to plot each of the basis functions in the model.
[11]:
def plot_spline_basis(basis, year, figsize=(10, 6)):
df = (
pd.DataFrame(basis)
.assign(year=year)
.melt("year", var_name="basis_idx", value_name="value")
)
_, ax = plt.subplots(figsize=figsize)
for idx in df.basis_idx.unique():
d = df[df.basis_idx == idx]
ax.plot(d["year"], d["value"])
return ax
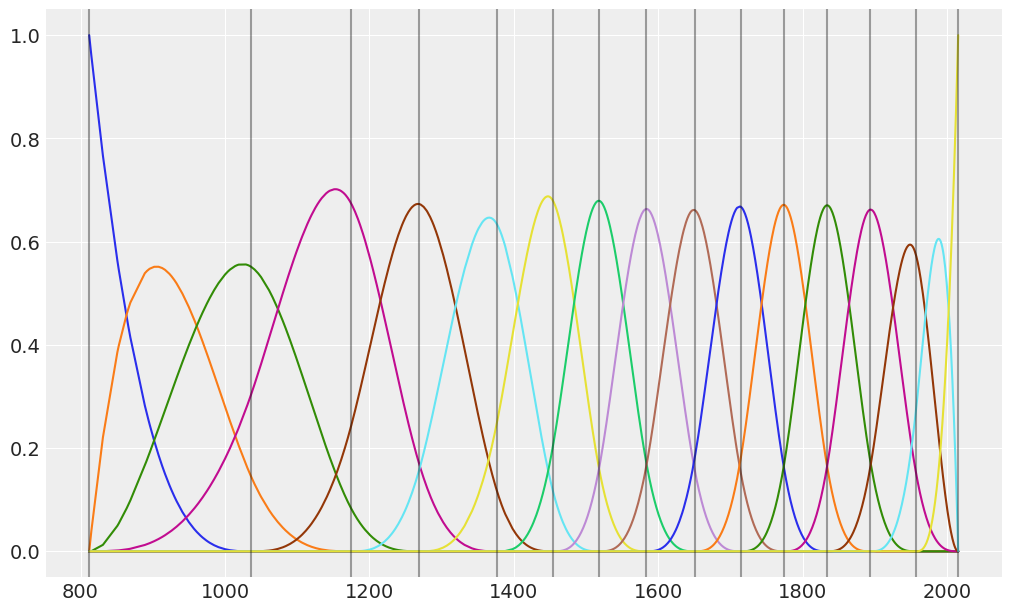
Below, we create a chart to visualize the b-spline basis. The overlap between the functions means that, at any given point in time, the regression function is influenced by more than one basis function. For example, if we look at the year 1200, we can see the regression line is going to be influenced mostly by the violet and brown functions, and to a lesser extent by the green and cyan ones. In summary, this is what enables us to capture local patterns in a smooth fashion.
[12]:
B = model._design.common["bs(year, knots = iknots, intercept = True)"]
ax = plot_spline_basis(B, data["year"].values)
plot_knots(knots, ax);
Fit model¶
Now we fit the model. In Bambi, it is as easy as calling the .fit() method on the Model instance.
[13]:
# The seed is to make results reproducible
idata = model.fit(random_seed=SEED)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [doy_sigma, bs(year, knots = iknots, intercept = True), Intercept]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 6 seconds.
The number of effective samples is smaller than 25% for some parameters.
Analisys of the results¶
It is always good to use az.summary() to verify parameter estimates as well as effective sample sizes and R hat values. In this case, the main goal is not to interpret the coefficients of the basis spline, but analyze the ess and r_hat diagnostics. In first place, effective sample sizes don’t look impressively high. Most of them are between 300 and 700, which is low compared to the 2000 draws obtained. The only exception is the residual standard deviation sigma. Finally, the
r_hat diagnostic is not always 1 for all the parameters, indicating there may be some issues with the mix of the chains.
[14]:
az.summary(idata)
[14]:
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 103.282 | 2.683 | 98.563 | 108.517 | 0.155 | 0.110 | 301.0 | 396.0 | 1.01 |
| bs(year, knots = iknots, intercept = True)[0] | -2.915 | 3.979 | -10.357 | 4.490 | 0.150 | 0.106 | 705.0 | 1318.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[1] | -0.691 | 4.179 | -8.630 | 6.762 | 0.177 | 0.126 | 556.0 | 1040.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[2] | -1.042 | 3.816 | -7.930 | 6.594 | 0.157 | 0.111 | 592.0 | 1098.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[3] | 4.955 | 3.224 | -1.356 | 10.471 | 0.157 | 0.111 | 420.0 | 739.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[4] | -0.813 | 3.104 | -6.947 | 4.704 | 0.154 | 0.109 | 410.0 | 740.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[5] | 4.417 | 3.244 | -1.769 | 10.277 | 0.158 | 0.112 | 420.0 | 648.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[6] | -5.270 | 3.071 | -10.686 | 0.691 | 0.157 | 0.111 | 383.0 | 733.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[7] | 7.901 | 3.121 | 1.994 | 13.688 | 0.160 | 0.113 | 379.0 | 757.0 | 1.01 |
| bs(year, knots = iknots, intercept = True)[8] | -0.947 | 3.149 | -7.128 | 4.572 | 0.159 | 0.113 | 394.0 | 732.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[9] | 3.115 | 3.175 | -3.170 | 8.936 | 0.159 | 0.112 | 400.0 | 833.0 | 1.01 |
| bs(year, knots = iknots, intercept = True)[10] | 4.749 | 3.196 | -0.664 | 11.388 | 0.162 | 0.115 | 390.0 | 766.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[11] | -0.049 | 3.129 | -5.615 | 5.873 | 0.157 | 0.111 | 398.0 | 844.0 | 1.01 |
| bs(year, knots = iknots, intercept = True)[12] | 5.564 | 3.129 | -0.425 | 11.330 | 0.156 | 0.111 | 403.0 | 629.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[13] | 0.818 | 3.248 | -5.549 | 6.543 | 0.163 | 0.115 | 398.0 | 841.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[14] | -0.733 | 3.559 | -7.719 | 5.777 | 0.157 | 0.111 | 515.0 | 795.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[15] | -6.851 | 3.593 | -13.625 | -0.195 | 0.162 | 0.118 | 488.0 | 812.0 | 1.00 |
| bs(year, knots = iknots, intercept = True)[16] | -7.532 | 3.495 | -13.780 | -0.806 | 0.157 | 0.111 | 498.0 | 987.0 | 1.00 |
| doy_sigma | 5.945 | 0.143 | 5.668 | 6.201 | 0.003 | 0.002 | 2169.0 | 1420.0 | 1.00 |
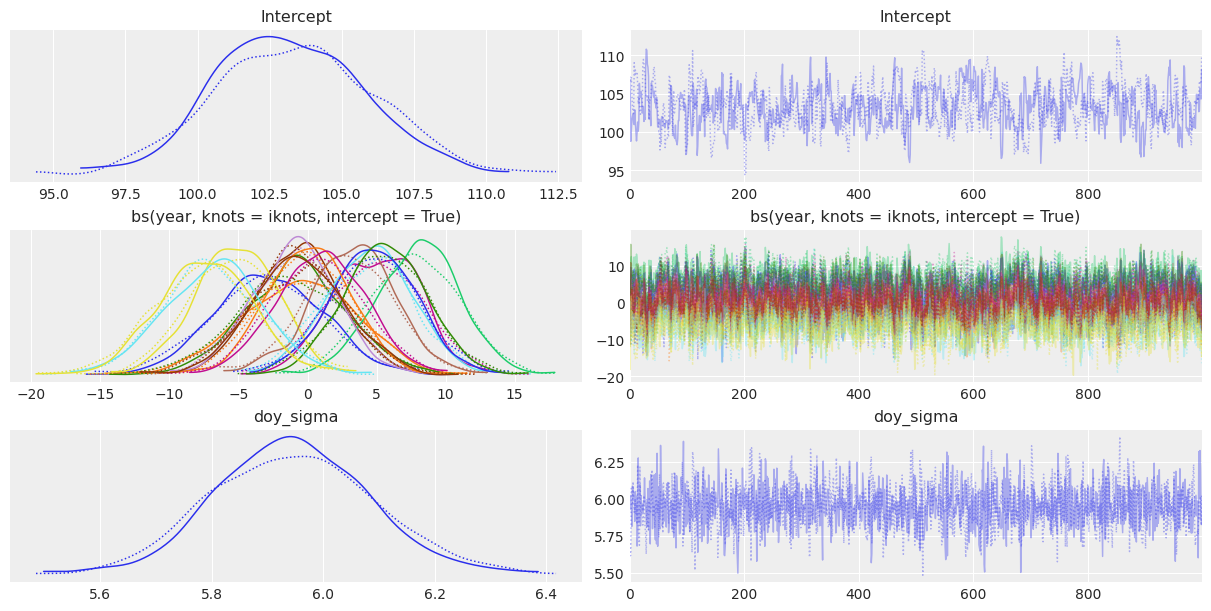
We can also use az.plot_trace() to visualize the marginal posteriors and the sampling paths. These traces show a stationary random pattern. If these paths were not random stationary, we would be concerned about the convergence of the chains.
[15]:
az.plot_trace(idata);
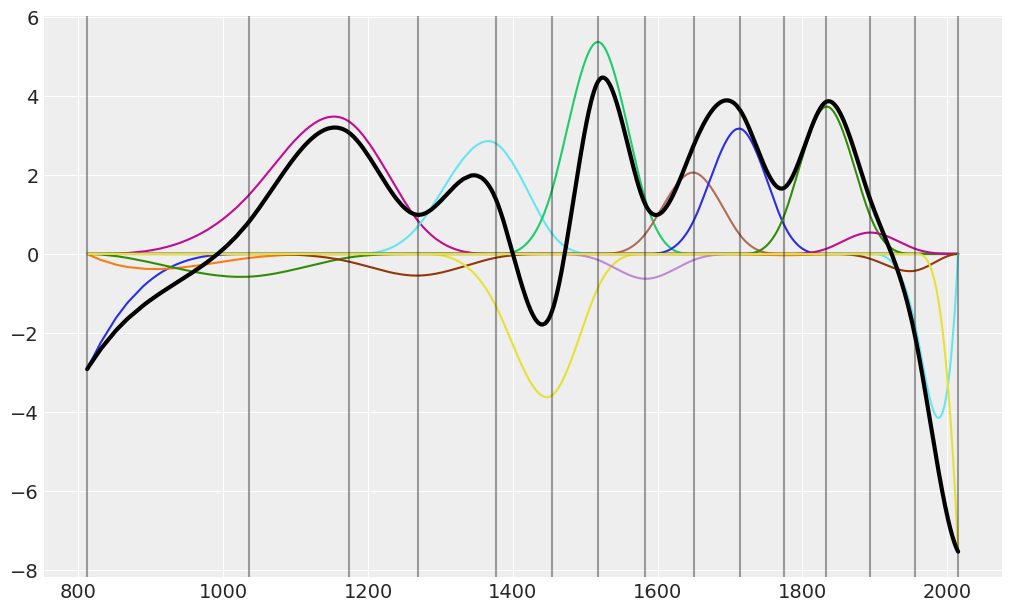
Now we can visualize the fitted basis functions. In addition, we include a thicker black line that represents the dot product between \(B\) and \(w\). This is the contribution of the b-spline to the linear predictor in the model.
[16]:
posterior_stacked = idata.posterior.stack(samples=["chain", "draw"])
wp = posterior_stacked["bs(year, knots = iknots, intercept = True)"].values.mean(1)
ax = plot_spline_basis(B * wp.T, data["year"].values)
ax.plot(data.year.values, np.dot(B, wp.T), color="black", lw=3)
plot_knots(knots, ax);
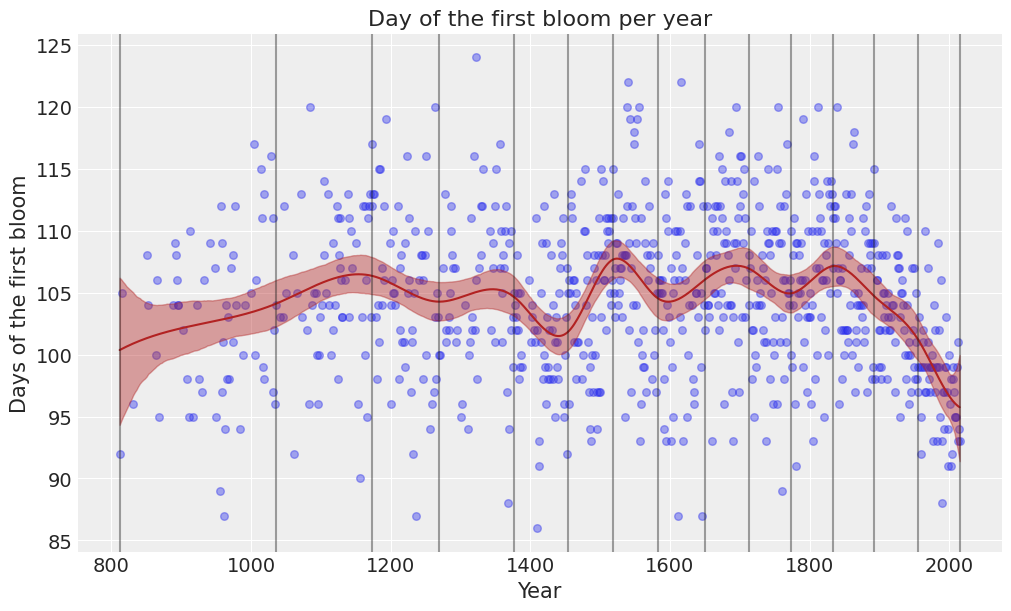
Plot predictions and credible bands¶
Let’s create a function to plot the predicted mean value as well as credible bands for it.
[17]:
def plot_predictions(data, idata, model):
# Create a test dataset with observations spanning the whole range of year
new_data = pd.DataFrame({"year": np.linspace(data.year.min(), data.year.max(), num=500)})
# Predict the day of first blossom
model.predict(idata, data=new_data)
posterior_stacked = idata.posterior.stack(samples=["chain", "draw"])
# Extract these predictions
y_hat = posterior_stacked["doy_mean"].values
# Compute the mean of the predictions, plotted as a single line.
y_hat_mean = y_hat.mean(1)
# Compute 94% credible intervals for the predictions, plotted as bands
hdi_data = np.quantile(y_hat, [0.03, 0.97], axis=1)
# Plot obserevd data
ax = plot_scatter(data)
# Plot predicted line
ax.plot(new_data["year"], y_hat_mean, color="firebrick")
# Plot credibility bands
ax.fill_between(new_data["year"], hdi_data[0], hdi_data[1], alpha=0.4, color="firebrick")
# Add knots
plot_knots(knots, ax)
return ax
[18]:
plot_predictions(data, idata, model);
Advanced: Watch out the underlying design matrix¶
We can write linear regression models in matrix form as
where \(\mathbf{y}\) is the response column vector of shape \((n, 1)\). \(\mathbf{X}\) is the design matrix that contains the values of the predictors for all the observations, of shape \((n, p)\). And \(\boldsymbol{\beta}\) is the column vector of regression coefficients of shape \((n, 1)\).
Because it’s not something that you’re supposed to consult regularly, Bambi does not expose the design matrix. However, with a some knowledge of the internals, it is possible to have access to it:
[19]:
np.round(model._design.common.design_matrix, 3)
[19]:
array([[1. , 1. , 0. , ..., 0. , 0. , 0. ],
[1. , 0.96 , 0.039, ..., 0. , 0. , 0. ],
[1. , 0.767, 0.221, ..., 0. , 0. , 0. ],
...,
[1. , 0. , 0. , ..., 0.002, 0.097, 0.902],
[1. , 0. , 0. , ..., 0. , 0.05 , 0.95 ],
[1. , 0. , 0. , ..., 0. , 0. , 1. ]])
Let’s have a look at its shape:
[20]:
model._design.common.design_matrix.shape
[20]:
(827, 18)
827 is the number of years we have data for, and 18 is the number of predictors/coefficients in the model. We have the first column of ones due to the Intercept term. Then, there are sixteen columns associated with the the basis functions. And finally, one extra column because we used span_intercept=True when calling the function bs() in the model formula.
Now we could compute the rank of the design matrix to check whether all the columns are linearly independent.
[21]:
np.linalg.matrix_rank(model._design.common.design_matrix)
[21]:
17
Since \(\text{rank}(\mathbf{X})\) is smaller than the number of columns, we conclude the columns in \(\mathbf{X}\) are not linearly independent.
If we have a second look at our code, we are going to figure out we’re spanning the intercept twice. The first time with the intercept term itself, and the second time in the spline basis.
This would have been a huge problem in a maximum likelihod estimation approach – we would have obtained an error instead of some parameter estimates. However, since we are doing Bayesian modeling, our priors ensured we obtain our regularized parameter estimates and everything seemed to work pretty well.
Nevertheless, we can still do better. Why would we want to span the intercept twice? Let’s create and fit the model again, this time without spanning the intercept in the spline basis.
[22]:
# Note we use the same priors
model_new = bmb.Model("doy ~ bs(year, knots=iknots)", data, priors=priors)
idata_new = model_new.fit(random_seed=7355608)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [doy_sigma, bs(year, knots = iknots), Intercept]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 6 seconds.
And let’s have a look at the summary
[23]:
az.summary(idata_new)
[23]:
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 102.442 | 1.973 | 98.592 | 105.918 | 0.094 | 0.066 | 444.0 | 670.0 | 1.0 |
| bs(year, knots = iknots)[0] | -0.970 | 3.974 | -7.562 | 7.715 | 0.155 | 0.110 | 658.0 | 1029.0 | 1.0 |
| bs(year, knots = iknots)[1] | 0.371 | 3.064 | -5.483 | 5.827 | 0.094 | 0.067 | 1056.0 | 1435.0 | 1.0 |
| bs(year, knots = iknots)[2] | 5.607 | 2.700 | 0.809 | 10.887 | 0.109 | 0.077 | 612.0 | 1203.0 | 1.0 |
| bs(year, knots = iknots)[3] | 0.195 | 2.513 | -4.433 | 4.984 | 0.095 | 0.067 | 705.0 | 1151.0 | 1.0 |
| bs(year, knots = iknots)[4] | 5.121 | 2.680 | 0.084 | 9.966 | 0.097 | 0.068 | 763.0 | 1329.0 | 1.0 |
| bs(year, knots = iknots)[5] | -4.383 | 2.506 | -9.044 | 0.295 | 0.099 | 0.070 | 647.0 | 1229.0 | 1.0 |
| bs(year, knots = iknots)[6] | 8.731 | 2.473 | 4.677 | 13.969 | 0.098 | 0.070 | 630.0 | 1149.0 | 1.0 |
| bs(year, knots = iknots)[7] | -0.125 | 2.588 | -4.902 | 4.540 | 0.099 | 0.070 | 683.0 | 1148.0 | 1.0 |
| bs(year, knots = iknots)[8] | 3.930 | 2.517 | -0.855 | 8.462 | 0.100 | 0.071 | 634.0 | 920.0 | 1.0 |
| bs(year, knots = iknots)[9] | 5.555 | 2.600 | 0.908 | 10.283 | 0.102 | 0.074 | 654.0 | 990.0 | 1.0 |
| bs(year, knots = iknots)[10] | 0.761 | 2.533 | -3.814 | 5.670 | 0.100 | 0.071 | 645.0 | 1156.0 | 1.0 |
| bs(year, knots = iknots)[11] | 6.430 | 2.626 | 1.552 | 11.423 | 0.103 | 0.073 | 661.0 | 1063.0 | 1.0 |
| bs(year, knots = iknots)[12] | 1.657 | 2.744 | -3.323 | 7.065 | 0.103 | 0.073 | 716.0 | 809.0 | 1.0 |
| bs(year, knots = iknots)[13] | 0.012 | 3.101 | -5.818 | 5.744 | 0.114 | 0.081 | 740.0 | 1479.0 | 1.0 |
| bs(year, knots = iknots)[14] | -6.015 | 3.163 | -11.873 | -0.135 | 0.113 | 0.080 | 791.0 | 934.0 | 1.0 |
| bs(year, knots = iknots)[15] | -6.854 | 3.025 | -12.477 | -1.243 | 0.106 | 0.075 | 803.0 | 1235.0 | 1.0 |
| doy_sigma | 5.946 | 0.144 | 5.686 | 6.213 | 0.003 | 0.002 | 2215.0 | 1552.0 | 1.0 |
There are a couple of things to remark here
There are 16 coefficients associated with the b-spline now because we’re not spanning the intercept.
The ESS numbers have improved in all cases. Notice the sampler isn’t raising any warning about low ESS.
r_hat coefficeints are still 1.
We can also compare the sampling times:
[24]:
idata.posterior.sampling_time
[24]:
6.127075433731079
[25]:
idata_new.posterior.sampling_time
[25]:
6.369754076004028
Sampling times are the same in this particular example. But in general, we expect the sampler to run faster when there aren’t structural dependencies in the design matrix.
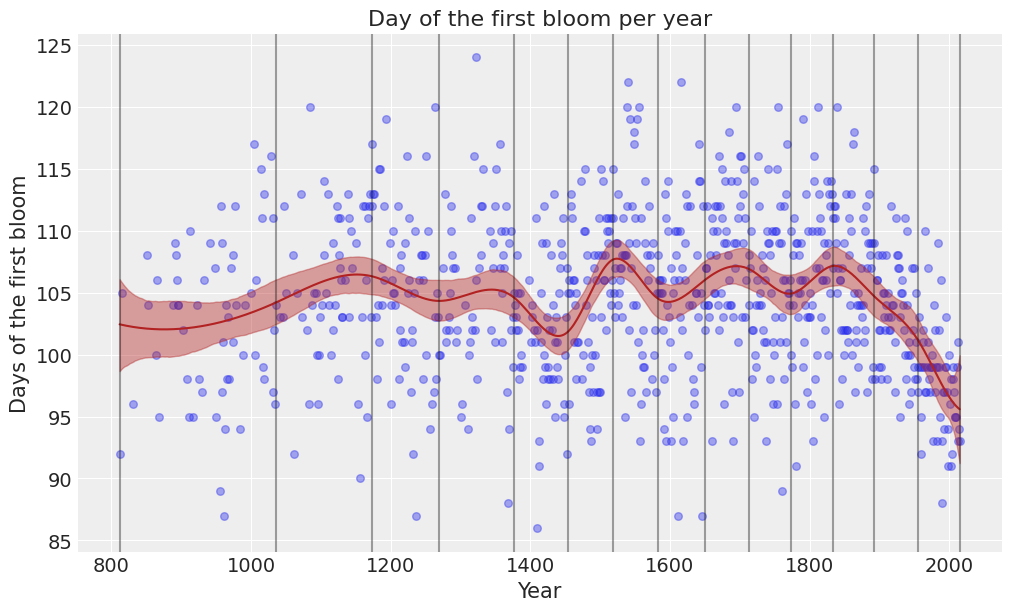
And what about predictions?
[26]:
plot_predictions(data, idata_new, model_new);
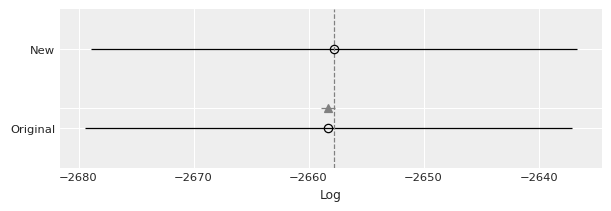
And model comparison?
[27]:
models_dict = {"Original": idata, "New": idata_new}
df_compare = az.compare(models_dict)
df_compare
[27]:
| rank | loo | p_loo | d_loo | weight | se | dse | warning | loo_scale | |
|---|---|---|---|---|---|---|---|---|---|
| New | 0 | -2657.807115 | 15.893960 | 0.000000 | 1.000000e+00 | 21.152109 | 0.000000 | False | log |
| Original | 1 | -2658.292451 | 16.598777 | 0.485336 | 3.330669e-16 | 21.180075 | 0.584776 | False | log |
[28]:
az.plot_compare(df_compare, insample_dev=False);
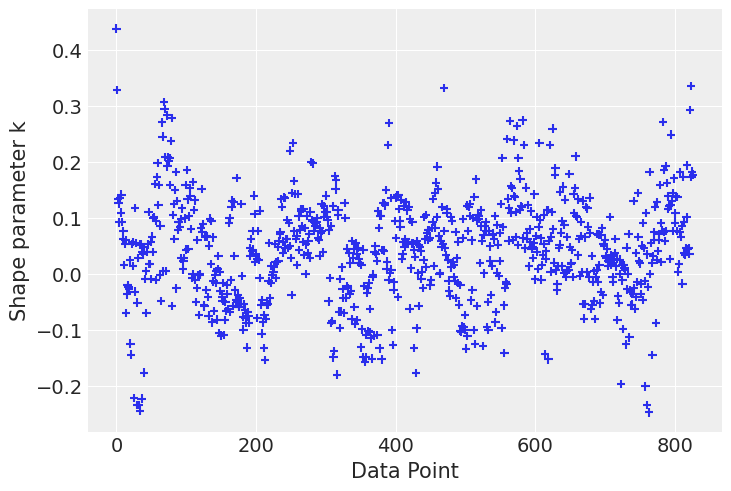
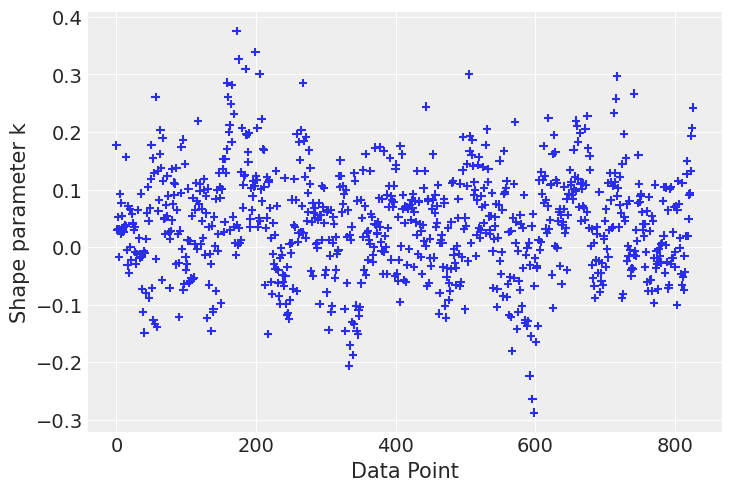
Finally let’s check influential points according to the k-hat value
[29]:
# Compute pointwise LOO
loo_1 = az.loo(idata, pointwise=True)
loo_2 = az.loo(idata_new, pointwise=True)
[30]:
# plot kappa values
az.plot_khat(loo_1.pareto_k);
[31]:
az.plot_khat(loo_2.pareto_k);
Final comments¶
Another option could have been to use stronger priors on the coefficients associated with the spline functions. For example, the example written in PyMC uses \(\text{Normal}(0, 3)\) priors on them instead of \(\text{Normal}(0, 10)\).
[32]:
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Sun Nov 14 2021
Python implementation: CPython
Python version : 3.8.5
IPython version : 7.18.1
matplotlib: 3.4.3
pandas : 1.3.1
sys : 3.8.5 (default, Sep 4 2020, 07:30:14)
[GCC 7.3.0]
numpy : 1.21.2
bambi : 0.6.3
arviz : 0.11.4
Watermark: 2.1.0