Bayesian Logistic Regression Example¶
[1]:
import arviz as az
import bambi as bmb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
[2]:
az.style.use('arviz-darkgrid')
Load and examine American National Election Studies (ANES) data¶
These data are from the 2016 pilot study. The full study consisted of 1200 people, but here we’ve selected the subset of 487 people who responded to a question about whether they would vote for Hillary Clinton or Donald Trump.
[3]:
data = pd.read_csv('data/ANES_2016_pilot.csv')
data.head()
[3]:
| vote | age | party_id | |
|---|---|---|---|
| 0 | clinton | 56 | democrat |
| 1 | trump | 65 | republican |
| 2 | clinton | 80 | democrat |
| 3 | trump | 38 | republican |
| 4 | trump | 60 | republican |
Our outcome variable is vote, which gives peoples’ responses to the following question prompt:
“If the 2016 presidential election were between Hillary Clinton for the Democrats and Donald Trump for the Republicans, would you vote for Hillary Clinton, Donald Trump, someone else, or probably not vote?”
[4]:
data['vote'].value_counts()
[4]:
clinton 215
trump 158
someone_else 48
Name: vote, dtype: int64
The two predictors we’ll examine are a respondent’s age and their political party affiliation, party_id, which is their response to the following question prompt:
“Generally speaking, do you usually think of yourself as a Republican, a Democrat, an independent, or what?”
[5]:
data['party_id'].value_counts()
[5]:
democrat 186
independent 138
republican 97
Name: party_id, dtype: int64
These two predictors are somewhat correlated, but not all that much:
[6]:
fig, ax = plt.subplots(3, figsize=(10, 6), constrained_layout=True)
key = dict(zip(data['party_id'].unique(), range(3)))
for label, df in data.groupby('party_id'):
ax[key[label]].hist(df['age'])
ax[key[label]].set_xlim([18, 90])
ax[key[label]].set_xlabel('Age')
ax[key[label]].set_ylabel('Frequency')
ax[key[label]].set_title(label)
ax[key[label]].axvline(df['age'].mean(), color='C1')
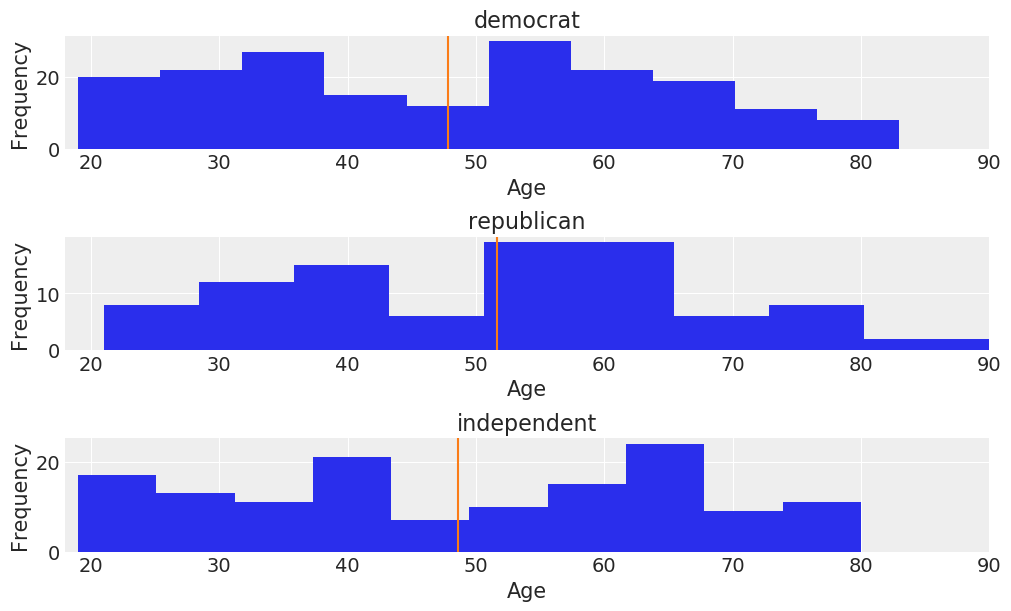
We can get a pretty clear idea of how party identification is related to voting intentions by just looking at a contingency table for these two variables:
[7]:
pd.crosstab(data['vote'], data['party_id'])
[7]:
| party_id | democrat | independent | republican |
|---|---|---|---|
| vote | |||
| clinton | 159 | 51 | 5 |
| someone_else | 10 | 22 | 16 |
| trump | 17 | 65 | 76 |
But our main question here will be: How is respondent age related to voting intentions, and is this relationship different for different party affiliations? For this we will need logistic regression.
Build clinton_model¶
To keep this simple, let’s look at only the data from people who indicated that they would vote for either Clinton or Trump, and we’ll model the probability of voting for Clinton.
[8]:
clinton_data = data.loc[data['vote'].isin(['clinton', 'trump']), :]
clinton_data.head()
[8]:
| vote | age | party_id | |
|---|---|---|---|
| 0 | clinton | 56 | democrat |
| 1 | trump | 65 | republican |
| 2 | clinton | 80 | democrat |
| 3 | trump | 38 | republican |
| 4 | trump | 60 | republican |
Specifying and fitting the model is simple. Notice the (optional) syntax that we use on the left-hand-side of the formula: We say vote[clinton] to instruct bambi that we wish the model the probability that vote=='clinton', rather than the probability that vote=='trump'. If we leave this unspecified, bambi will just pick one of the events to model, but will inform you which one it picked when you build the model (and again when you look at model summaries.)
When fitting models using the pymc3 backend, the default estimation strategy is to start with an identity mass matrix, but add uniform jitter in [-1, 1] and then adapt a diagonal based on the variance of the tuning samples. This generally works quite well, but occasionally it can fails. That’s what was happening for this particular data set and model, so below we disable the jitter+adapt_diag initialization by changing from init='auto' (the default) to init=adapt_diag, which
tells the pymc3 backend to drop the jitter step.
[9]:
clinton_model = bmb.Model(clinton_data)
clinton_fitted = clinton_model.fit('vote[clinton] ~ party_id + party_id:age',
family='bernoulli', samples=1000, init='adapt_diag')
/home/osvaldo/anaconda3/lib/python3.7/site-packages/pandas/core/frame.py:2963: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self[k1] = value[k2]
INFO:numexpr.utils:NumExpr defaulting to 4 threads.
/home/osvaldo/proyectos/00_BM/Bambi/bambi/bambi/models.py:269: UserWarning: Modeling the probability that vote=='clinton'
self.y.name, str(self.clean_data[self.y.name].iloc[event])
Auto-assigning NUTS sampler...
INFO:pymc3:Auto-assigning NUTS sampler...
Initializing NUTS using adapt_diag...
INFO:pymc3:Initializing NUTS using adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
INFO:pymc3:Multiprocess sampling (2 chains in 2 jobs)
NUTS: [party_id:age, party_id, Intercept]
INFO:pymc3:NUTS: [party_id:age, party_id, Intercept]
Since we didn’t explicitly set any of the prior distributions, here’s a view of what the default priors look like for all parameters:
[10]:
clinton_model.plot();
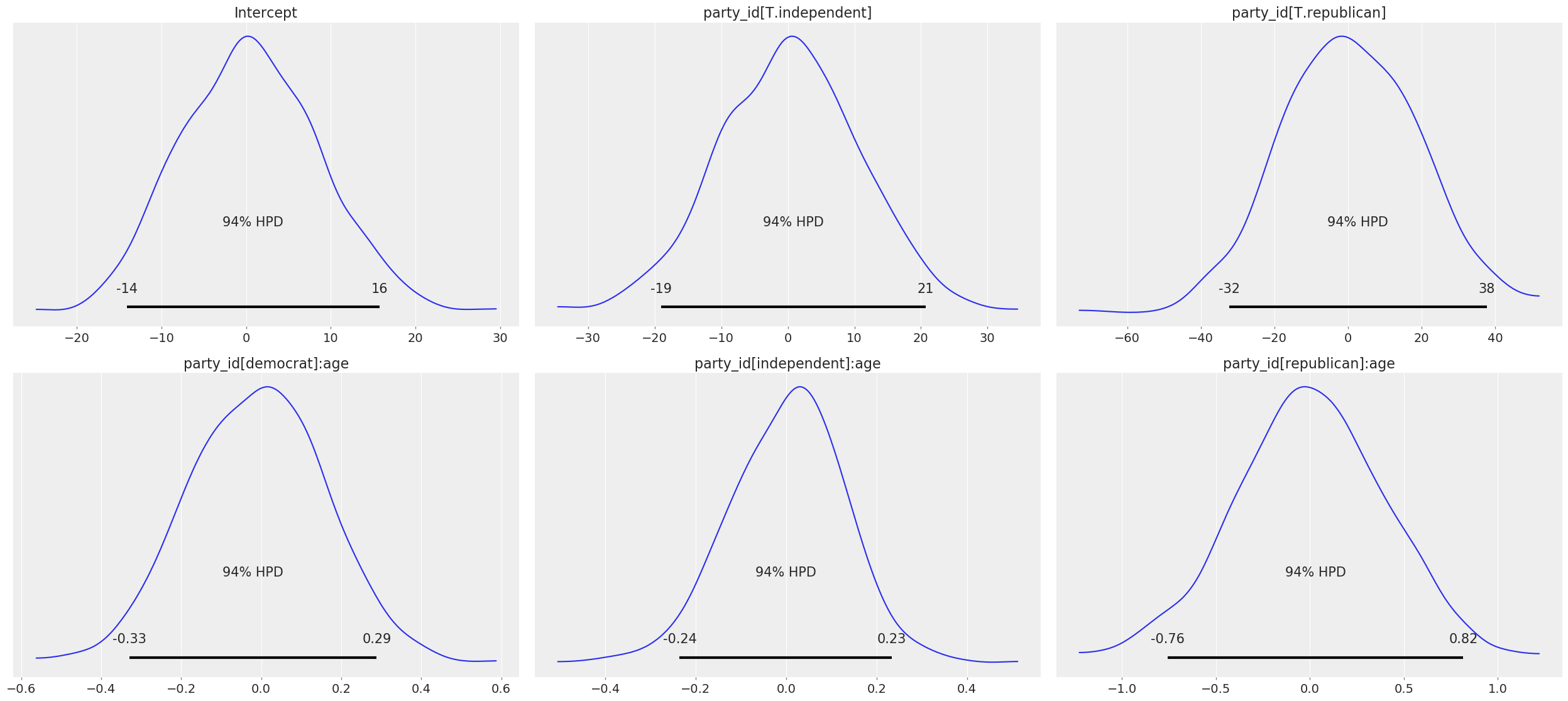
[11]:
{x.name: x.prior.args for x in clinton_model.terms.values()}
[11]:
{'Intercept': {'mu': array([0.308043]), 'sd': array([8.39859892])},
'party_id': {'mu': array([0, 0]), 'sd': array([10.51415445, 18.72417819])},
'party_id:age': {'mu': array([0, 0, 0]),
'sd': array([0.16748696, 0.12909332, 0.40771782])}}
Some more info about these default priors can be found in this technical paper.
Now let’s check out the the results!
[12]:
az.plot_trace(clinton_fitted);
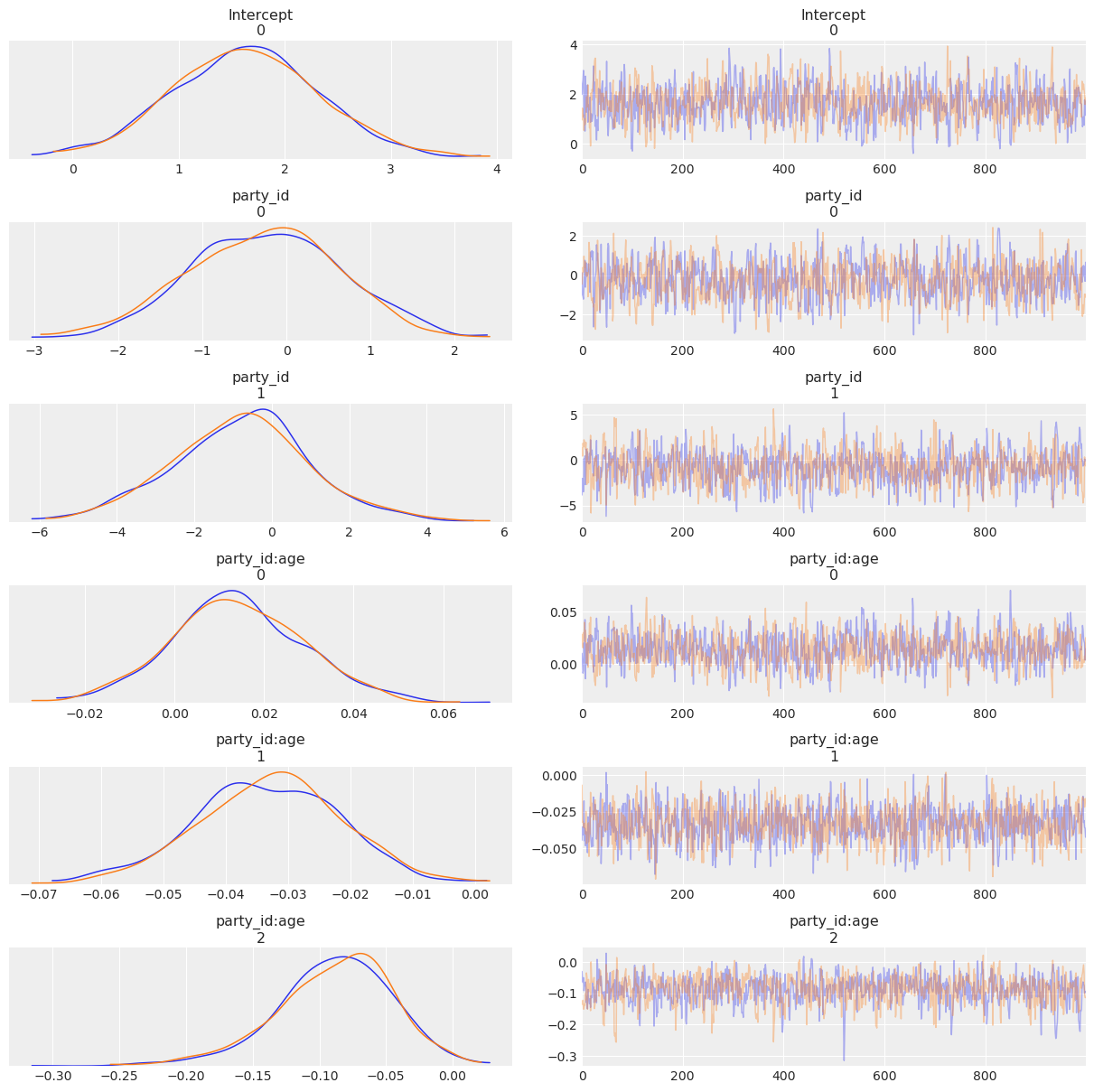
[13]:
az.summary(clinton_fitted)
[13]:
| mean | sd | hpd_3% | hpd_97% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Intercept[0] | 1.638 | 0.702 | 0.373 | 3.031 | 0.025 | 0.017 | 807.0 | 807.0 | 808.0 | 933.0 | 1.0 |
| party_id[0] | -0.257 | 0.924 | -2.055 | 1.376 | 0.033 | 0.023 | 790.0 | 787.0 | 792.0 | 971.0 | 1.0 |
| party_id[1] | -0.790 | 1.774 | -4.172 | 2.668 | 0.062 | 0.044 | 816.0 | 816.0 | 824.0 | 908.0 | 1.0 |
| party_id:age[0] | 0.014 | 0.015 | -0.014 | 0.042 | 0.001 | 0.000 | 840.0 | 840.0 | 839.0 | 977.0 | 1.0 |
| party_id:age[1] | -0.033 | 0.012 | -0.056 | -0.012 | 0.000 | 0.000 | 1193.0 | 1190.0 | 1192.0 | 1115.0 | 1.0 |
| party_id:age[2] | -0.089 | 0.043 | -0.170 | -0.007 | 0.001 | 0.001 | 873.0 | 772.0 | 919.0 | 858.0 | 1.0 |
Run Inference¶
Grab the posteriors samples of the age slopes for the three party_id categories.
[14]:
#we need to automatically add labels to InferenceData object to recover this by_label selection
parties = ['democrat', 'independent', 'republican']
parti_idx = [0, 1, 2]
dem, ind, rep = [clinton_fitted.posterior['party_id:age'][:,:,x].values
for x in parti_idx]
[15]:
for idx, x in enumerate([dem, ind, rep]):
ax = az.plot_kde(x, label=f'{parties[idx]}', plot_kwargs={'color':f'C{idx}'})
ax.legend(loc='upper left');
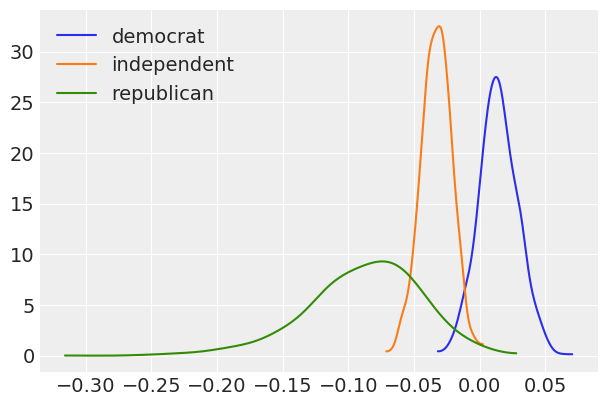
What is the probability that the Democrat slope is greater than the Republican slope?
[16]:
(dem > rep).mean()
[16]:
0.994
Probability that the Democrat slope is greater than the Independent slope?
[17]:
(dem > ind).mean()
[17]:
0.994
Probability that the Independent slope is greater than the Republican slope?
[18]:
(ind > rep).mean()
[18]:
0.9055
Probability that the Democrat slope is greater than 0?
[19]:
(dem > 0).mean()
[19]:
0.8395
Probability that the Republican slope is less than 0?
[20]:
(rep < 0).mean()
[20]:
0.9895
Probability that the Independent slope is less than 0?
[21]:
(ind < 0).mean()
[21]:
0.9975
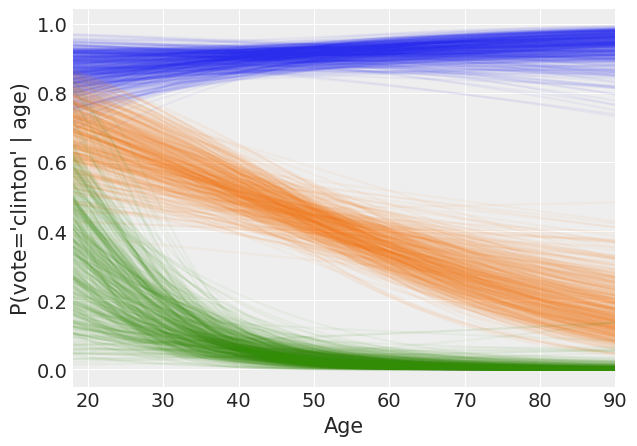
Spaghetti plot of model predictions¶
Separate results into two, one containing the intercept for each party_id, the other containing the age slopes for each party_id.
[22]:
slopes = clinton_fitted.posterior['party_id:age'].values.reshape(2000, 3).T
[23]:
intercept_dem = clinton_fitted.posterior['Intercept'].squeeze().values.reshape(-1,)
intercept_ind = intercept_dem + clinton_fitted.posterior['party_id'][:,:,0].values.reshape(-1,)
intercept_rep = intercept_dem + clinton_fitted.posterior['party_id'][:,:,1].values.reshape(-1,)
intercepts = [intercept_dem, intercept_ind, intercept_rep]
Compute the predicted values for each posterior sample.
[24]:
def invlogit(x):
return 1/(1+np.exp(-x))
X = np.hstack([np.array([1]*len(np.arange(18, 91)))[:, None], np.arange(18, 91)[:, None]])
yhat = [invlogit(np.dot(X, np.vstack([intercepts[i], slopes[i]]))) for i in range(3)]
Make the plot!
[25]:
_, axes = plt.subplots(figsize=(7, 5))
for i in range(3):
for t in range(500):
axes.plot(X[:, 1], yhat[i][:, t], alpha=0.05, color=f'C{i}')
axes.set_ylabel('P(vote=\'clinton\' | age)')
axes.set_xlabel('Age', fontsize=15)
axes.set_xlim(18, 90);